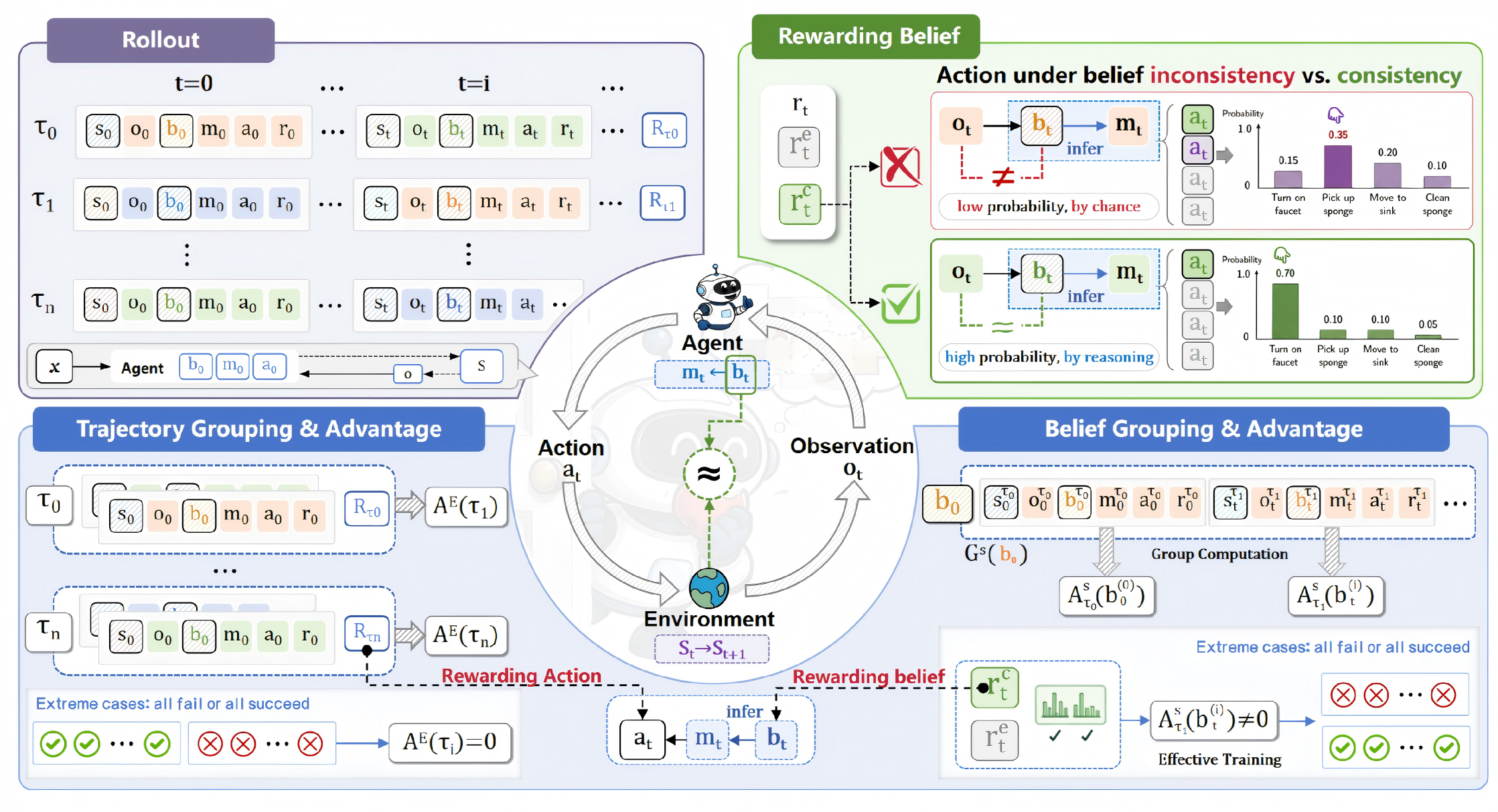
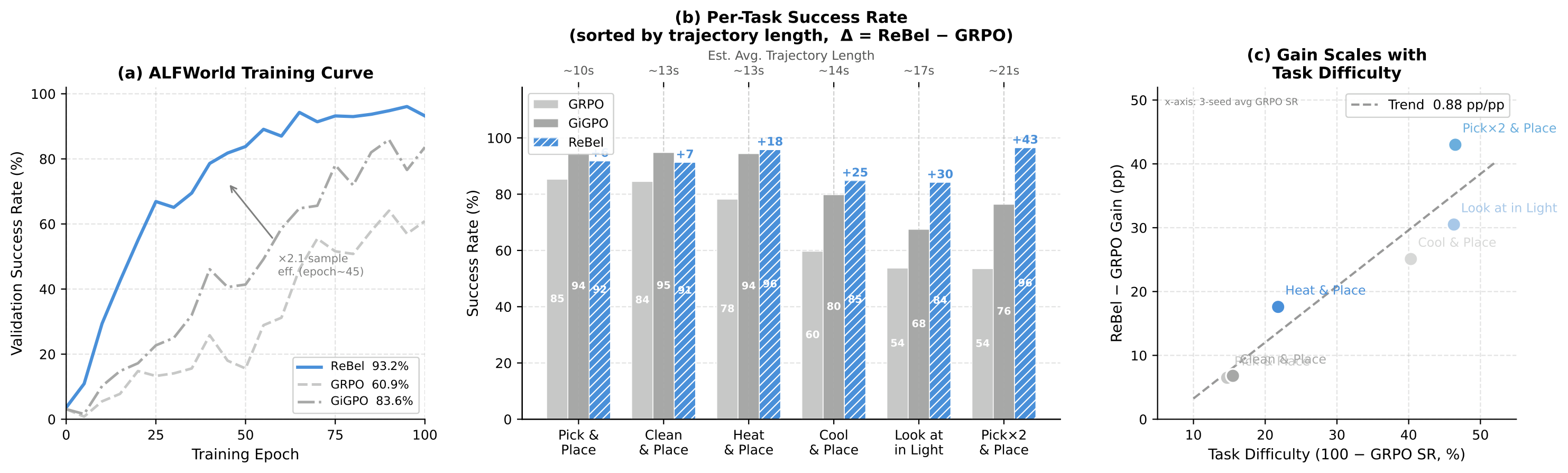
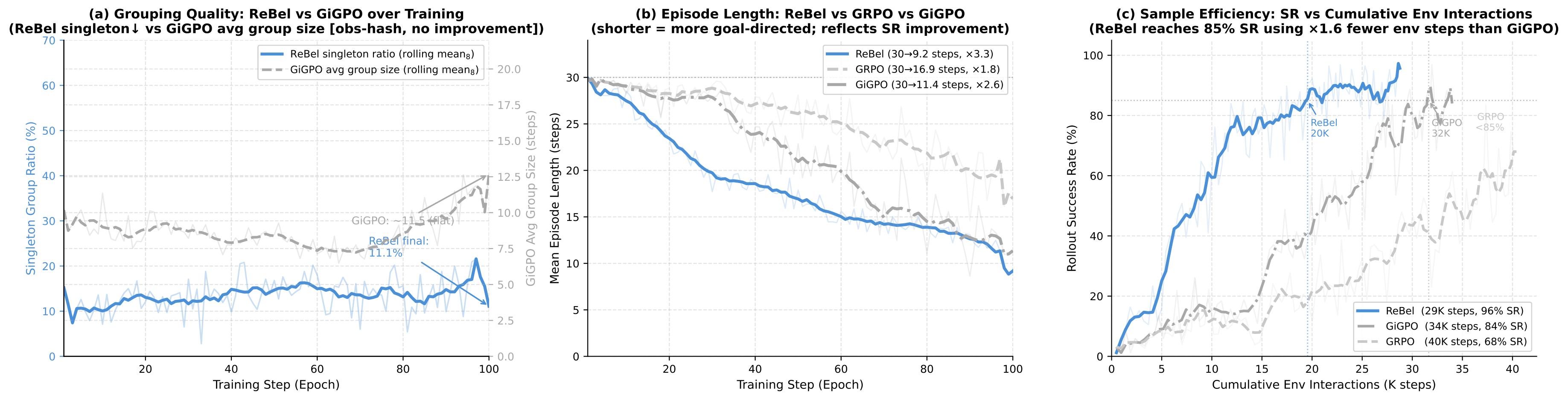
The World Model Hypothesis
Every capable agent maintains a world model — a compressed, structured representation of the environment used to reason, anticipate, and plan. Standard LLM agents bury this model inside opaque hidden states where it is invisible to credit assignment and free to drift without consequence. ReBel externalizes the world model as a structured belief segment, making it a first-class object that can be supervised, verified against observations, and corrected when wrong. This is a minimal but concrete instantiation of the world-model loop.
The Failure: Belief Drift
In partially observable environments, agents infer latent state from incomplete observations. Small inference errors compound over 30+ steps into belief drift — the agent thinks it holds an apple, but its hands are empty. Delayed terminal rewards can't trace the failure back to the original misinference. Credit assignment collapses.
The Fix: Belief as First-Class Variable
ReBel makes belief explicit, structured, and verifiable. At each step, the agent outputs a structured belief (object locations, states, task phase, predictions) alongside its reasoning. This belief is checked against subsequent observations — mismatches produce immediate, dense learning signals.
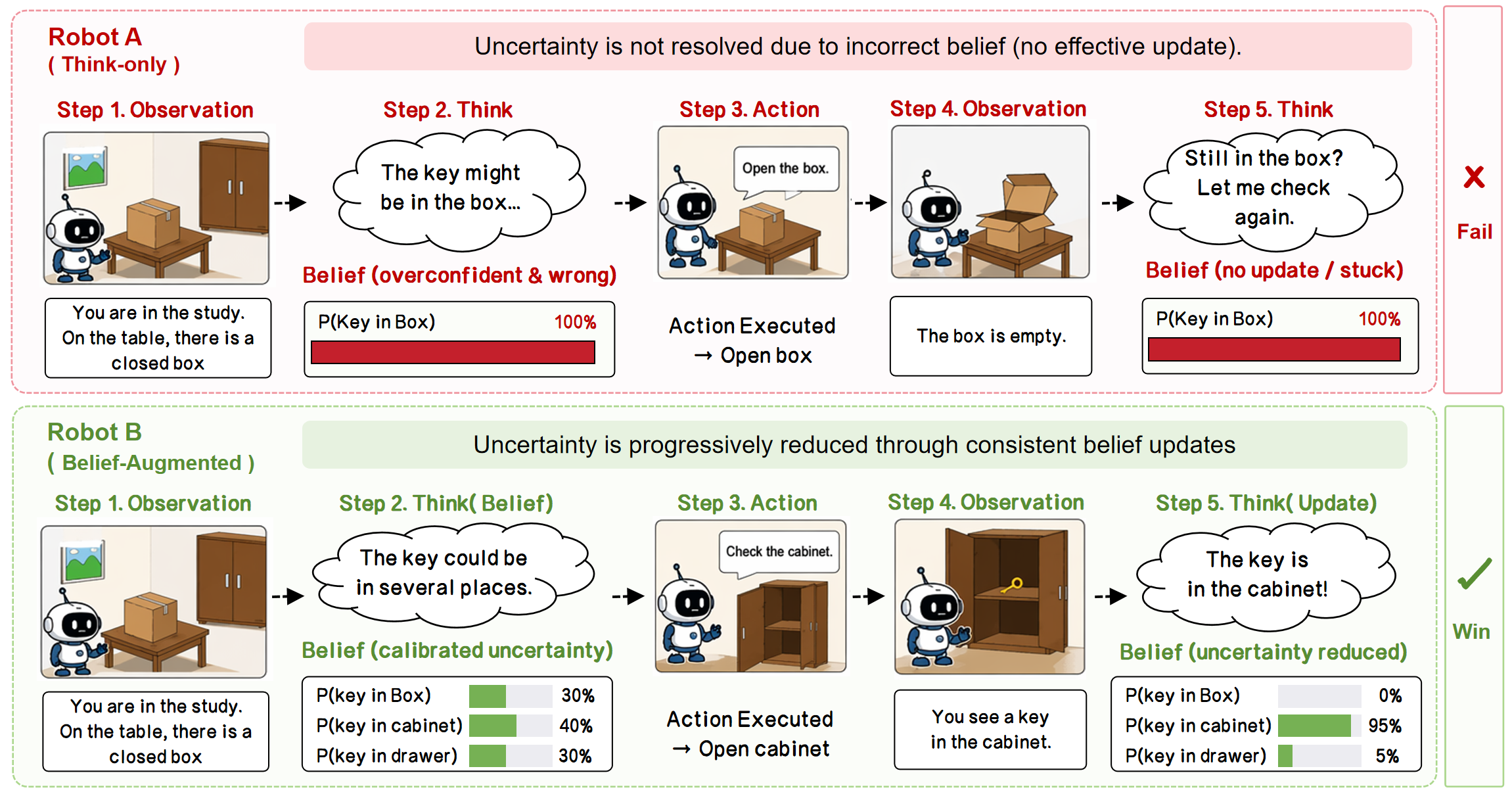
Belief inconsistency (left) vs. ReBel's consistent belief tracking (right). When the internal world model drifts, actions become invalid even with confident token probabilities. ReBel eliminates this failure mode.